![]() Chrome 11 beta release has introduced support for the HTML speech input API. In Google Chrome 11 beta, you can translate what you say in English into other languages with Google Translate.
Chrome 11 beta release has introduced support for the HTML speech input API. In Google Chrome 11 beta, you can translate what you say in English into other languages with Google Translate.
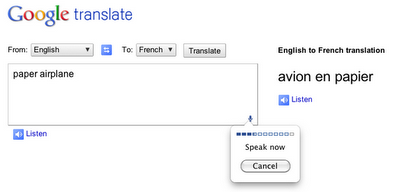
A microphone icon is shown on the bottom right of the input box when you select English as the language. Click on the microphone icon and speak your text. The text you speak is displayed on the textbox. Choose the language you want the text to translate to. You can even click on “Listen” to hear the translated words spoken back to you!
Right now, this feature only works for English, so you need to select “English” from the list of input languages.
When a web page uses this feature, you simply click on an icon and then speak into your computer’s microphone. The recorded audio is sent to speech servers for transcription, after which the text is typed out for you. Try it out yourself in this little demo. Chrome beta release also offers a sneak peek of GPU-accelerated 3D CSS, which allows developers to apply slick 3D effects to web page content using CSS.
With this API, developers can give web apps the ability to transcribe your voice to text.
[advt]Speech input through HTML is one of many new web technologies in the browser that help make innovative and useful web applications like Google Translate’s speech feature possible. If you’d like to check out more examples of applications built using the latest and greatest web technologies in the browser
About HTML Speech Input API
he HTML Speech Input API aims to provide web developers with features that are typically not available when using standard speech recognition software to replace keyboard input in a web browser. The API itself is agnostic of the underlying speech recognition implementation and can support both server based as well as embedded recognizers. The API is designed to enable both one-off speech input and continuous speech input requests. Speech recognition results are provided to the web page as a list of hypotheses along with other relevant information for each hypothesis.
Automatic actions at the end of a spoken input
This API allows web applications to be notified at the completion of successful and failed speech input. For e.g. at the end of a successful speech input session, a web application could perform:
- Safe and idempotent actions, e.g. search or web site navigation. The actions have no side effects, and the cost of correcting the action is very low, e.g. by editing the query on the search results page or going back in the browser history.
- Undoable actions, e.g. archiving e-mail or editing a document. It is ok to take action immediately, since actions can be easily undone, e.g. by an undo option in the app.
- Final, time critical, but not dangerous actions, e.g. game inputs. These actions cannot be undone, but ease or speed of input is more important than correctness.
- Final and dangerous actions, e.g. composing and sending a message (e-mail, SMS, IM, etc). Actions cannot be undone, so the user must be able to verify the action before it is taken.
Types 1, 2 & 3 work best when the web page can take action immediately at the end of speech input. This requires some facility other than a purely transparent speech input method that simulates keyboard input, since web pages typically do not want to take actions directly on text ‘change’ events.
Speech recognition grammars
This API allows web applications to specify grammars that the speech recognizer should use when recognizing the user’s speech. Specifying a grammar is useful for apps which have limited vocabulary, for e.g. commands, navigation within page, maps etc. Such applications would not work as well with free-form text input. The existing HTML attribute pattern can be used to restrict the allowed inputs, but regular expressions are less expressive than context-free grammars. Also, SRGS grammars can include semantic annotations.
Application-specific handling of speech recognition hypotheses
This API gives the web application access to more information than just the most likely recognized utterance. Some applications can provide a better user experience when they have access to the list of recognition hypotheses produced by the speech recognizer. For example:
- A web search application can accept speech input, and perform a search immediately when the input is recognized. If it has access to the additional recognition hypothesis (aka N-best list), it can display that on the search results page and let the user chose the correct query if the input was misrecognized. For example, Google search might display search results for “recognize speech”, and show a link with the text “Did you say ‘wreck a nice beach’?”.
- An application may accept input that can only be validated programmatically (i.e. that can’t be expressed with a regular expression or a context free grammar). Examples may include credit card numbers, user names etc. In order to check that a certain combination of digits form a valid credit card number one can apply a simple algorithm to the input. Given a set of recognition hypotheses, the app can eliminate the invalid inputs by applying the algorithm and looking at the result.[source]

Be the first to comment